10天了诶……
<题面链接> 提取码:7puf
Part1. 游记
为什么就过了 10 天了啊?
好颓废啊!
还有 5天就可以走了诶,我好开心啊好想再在这里再多学几天啊(emm……)
游记欠了好多啊……关键是好多事情都忘了……
同学都好神仙啊,把一道 IOI 的原题在考场上都做对了(一群人fake带着微笑说“我好菜啊,我爆零了”,然后最后发现真正爆炸的只有自己一个)
Part2. Solution
还是以题解为主……(好无聊啊)
T1. 数学题(math)
[Experience]
推式子推得很开心,一开始就没想过要写正解,就朝着 60% 的分数去写……
感觉什么问题都没有,不知道哪里写炸了……
后来听讲题,是一个神奇的二维GCD??反正我是没听懂,还好后来有一个神仙暴力剪枝踩标算(听说时间复杂度有问题,但是我看它跑得飞快),就写了那种写法。
[Solution]
= 60pt
如果你学过(或者知道)向量加,你可以知道我们其实就是要求:
的最小值。
于是就开始从这个式子开始推倒导:
我们发现如果我们确认了 $\lambda_1$ (即把 $\lambda_1$ 看作常数),那么上式就是关于 $\lambda_2$ 的一元二次式,我们要求该式子的极值,则我们可以利用二次函数的性质,找到二次函数的顶点,就可以使式子取到极值。但是由于 $\lambda_2$ 只能取整数、而二次函数的顶点不一定是整点坐标,所以 $\lambda_2$ 的取值要在顶点左右试一下……
由于 $60\%$ 的数据满足 $\min\{|\lambda_1|,|\lambda_2|\}\leq30$,所以我们只需要枚举 $\lambda_1\in[-30,30]$ 以及 $\lambda_2\in[-30,30]$ 即可。
上面是 60pt 的做法,100pt 需要在上面的式子上再作推导。
= 100pt
把该式子看作关于 $\lambda_1$ 的一元二次函数,即 $\lambda_2$ 为参数,则有
令 $A=x_1^2+y_1^2$,$B=x_1x_2+y_1y_2$,$C=x_2^2+y_2^2$;则
这是二次函数的一般式,那么我们把它化成 顶点式:
当 $\lambda_1+\frac BA\lambda_2=0$ 时,$f(\lambda_1)$ 取到最小值为 $\frac{AC-B^2}A\cdot \lambda_2^2$。
首先可以证明 $AC-B^2>0$ ,代入即可证明,所以 $\frac{AC-B^2}{A}\lambda_2^2$ 随着 $\lambda_2^2$ 的增大而增大 ,且由于 $\lambda_2^2$ 增长速度很快,所以如果我们从小到大枚举 $\lambda_2^2$,在某一次计算中发现 $\frac{AC-B^2}{A}\lambda_2^2>ans$ ($ans$ 是当前已经计算出的最小答案),就可以直接剪枝,不再枚举,因为 $\frac{AC-B^2}{A}\lambda_2^2$ 是函数最小值,如果最小值都大于当前答案,以后函数的取值都不可能更小。
期望得分 100pt
[Source]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long ll;
ll ans,xa,ya,xb,yb;
int main(){
freopen("math.in","r",stdin);
freopen("math.out","w",stdout);
while(~scanf("%lld%lld%lld%lld",&xa,&ya,&xb,&yb)){
ans=(1ll<<60);
ll A=xb*xb+yb*yb,
B=xa*xb+ya*yb,
C=xa*xa+ya*ya;
int ka=0;
while(true){
double cur=1.0*(A*C-B*B)/A;
if(cur*ka*ka>=ans) break;
int kb_=B*ka/A;
for(int i=-1;i<=1;i++){
int kb=kb_+i;
if(kb || ka) ans=min(ans,(ka*xa+kb*xb)*(ka*xa+kb*xb)+(ka*ya+kb*yb)*(ka*ya+kb*yb));
}
kb_=-B*ka/A;
for(int i=-1;i<=1;i++){
int kb=kb_+i;
if(kb || ka) ans=min(ans,(ka*xa+kb*xb)*(ka*xa+kb*xb)+(ka*ya+kb*yb)*(ka*ya+kb*yb));
}
ka++;
}
printf("%lld\n",ans);
}
return 0;
}
|
T2. 挖宝藏(treasure)
[Experience]
果然还是状压 DP……考场上没有想到转移,就只好写了一个用区间 DP 求解的部分分……
[Solution]
= 简述方案
由于每一层相对独立(只能从上一层转移到当前层),且每一层的宝藏数只有 $9$ 个,考虑对每一层状态压缩。
f[S][i][j][k] 表示当前在第 k 层的 (i,j) 处,已经获得的宝藏为 S(压缩状态),考虑以下两种转移:
- 你现在已经获得了
S 的宝藏,在第 k 层的 (i,j) 处,然后你带着这些宝藏在第 k 层到处跑,但是不获得其他宝藏(可以理解为“可以经过有宝藏的位置,但是不拿宝藏”),这样的话我们就可以由 f[S][i][j][k] 更新到 f[S][i'][j'][k] ,似乎有后效性,可以用最短路来转移。
- 你从
(i,j) 出发,先挖开 (i,j),获得了 S1 的宝藏并回到 (i,j),又从 (i,j) 出发获得了 S2 的宝藏并回到 (i,j) ,现在你在 (i,j),获得的宝藏为 S1 和 S2 的并集(保证 S1 与 S2 无交集),这样的话就可以从 f[S1][i][j][k],f[S2][i][j][k] 转移到 f[S][i][j][k] 了。
那么具体怎么转移呢?
= 转移 1
这一种转移要在我们已经求解完 f[S][i][j][k] 中的所有 [i][j] 的值时才转移——我们把每一个 (i,j) 都当作源点,尝试更新其他的 f[S][i][j][k]。
转移的时候,比如从 f[S][i][j][k] 转移到 f[S][p][q][k] ((p,q) 和 (i,j) 相邻),我们假设 (p,q) 这个点原来没去过,所以我们要先把它挖开,花费 a[k][p][q] 的代价,也就是说 f[S][p][q][k]=min(f[S][p][q][k],f[S][i][j][k]+a[k][p][q])。
Q:为什么可以直接假设 (p,q) 没有去过,要挖开呢?这样不是会有一些不合法的代价吗?
A:的确 (p,q) 可能之前去过而不需要重新挖开,也就是说这样转移可能会有重复计算的花费,但是一定会有比这种错误的转移更优的转移(也就是没有重复计算花费的转移)会替代掉它。所以最后留下来的最小花费是一个合法的花费。
= 转移 2
字面上理解,就是:
1
| f[S][i][j][k]=min(f[S][i][j][k],f[S'][i][j][k]+f[S-S'][i][j][k]-a[k][i][j])
|
最后减去 a[k][i][j] 是因为状态 f[S'][i][j][k] 和 f[S-S'][i][j][k] 都考虑了“先挖开 (i,j)”,也就是说 (i,j) 被挖了两遍,实际上第二遍是不需要挖的,所以减去一次挖开 (i,j) 的花费。
然后有一种特别的情况:(i,j) 处本来就有一个宝藏 t;
这个时候,我们把 f[t][i][j][k] 的初值赋为 a[k][i][j] ,虽然从道理上很难理解,但是看转移式:
1
| f[t][i][j][k] + f[S-t][i][j][k] - a[k][i][j] ---> f[S-t][i][j][k]
|
也就是说挖到 (i,j) 时就自然而然地获得了 (i,j) 处的宝藏 t ,不需要额外的花费。
= 层与层之间
我们考虑在每一层新建一个宝藏 0 ,替代该层上方所有层的宝藏,我们只有拿完一层的所有宝藏才能下到下一层。而我们到达新的一层时,就默认已经获得了宝藏 0(因为我们把上方所有的宝藏都拿完了)。
这样转移会方便许多。
[Source]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
#include<queue>
#include<vector>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=10;
const int DIR[4][2]={{0,1},{1,0},{0,-1},{-1,0}};
struct PAIR{
int x,y;
PAIR(){}
PAIR(int _x,int _y):x(_x),y(_y){}
};
int cel,rol,col;
bool vis[N+3][N+3];
int cst[N+3][N+3][N+3],idwnt[N+3][N+3][N+3],f[(1<<N)+3][N+3][N+3][N+3];
vector<PAIR> wnt[N+3];
queue<PAIR> que;
int main(){
freopen("treasure.in","r",stdin);
freopen("treasure.out","w",stdout);
scanf("%d%d%d",&cel,&rol,&col);
for(int i=1;i<=cel;i++)
for(int j=1;j<=rol;j++)
for(int k=1;k<=col;k++)
scanf("%d",&cst[i][j][k]);
for(int i=1;i<=cel;i++){
int nwnt;scanf("%d",&nwnt);
for(int j=1;j<=nwnt;j++){
int x,y;scanf("%d%d",&x,&y);
wnt[i].push_back(PAIR(x,y));
idwnt[i][x][y]=j;
}
}
memset(f,0x3f,sizeof f);
int inf=f[0][0][0][0];
for(int z=1;z<=cel;z++){
int Sall=(1<<wnt[z].size()+1)-1,LSall=(1<<wnt[z-1].size()+1)-1;
for(int x=1;x<=rol;x++)
for(int y=1;y<=col;y++){
if(z==1) f[1][z][x][y]=cst[z][x][y];
else f[1][z][x][y]=f[LSall][z-1][x][y]+cst[z][x][y];
if(idwnt[z][x][y]) f[1<<idwnt[z][x][y]][z][x][y]=cst[z][x][y];
}
for(int S=1;S<=Sall;S++){
for(int x=1;x<=rol;x++)
for(int y=1;y<=col;y++){
for(int T=(S-1)&S;T;T=(T-1)&S)
f[S][z][x][y]=min(f[S][z][x][y],f[T][z][x][y]+f[S^T][z][x][y]-cst[z][x][y]);
if(f[S][z][x][y]!=inf){
que.push(PAIR(x,y));
vis[x][y]=true;
}
}
while(!que.empty()){
PAIR u=que.front();que.pop();
vis[u.x][u.y]=false;
for(int i=0;i<4;i++){
PAIR v=PAIR(u.x+DIR[i][0],u.y+DIR[i][1]);
if(v.x<1 || v.x>rol || v.y<1 || v.y>col) continue;
if(f[S][z][v.x][v.y]>f[S][z][u.x][u.y]+cst[z][v.x][v.y]){
f[S][z][v.x][v.y]=f[S][z][u.x][u.y]+cst[z][v.x][v.y];
if(!vis[v.x][v.y]){
vis[v.x][v.y]=true;
que.push(PAIR(v.x,v.y));
}
}
}
}
}
}
int ans=inf;
int Sall=(1<<wnt[cel].size()+1)-1;
for(int x=1;x<=rol;x++)
for(int y=1;y<=col;y++)
ans=min(ans,f[Sall][cel][x][y]);
printf("%d\n",ans);
return 0;
}
|
T3. 理想城市(city)
[Experience]
倒是想法跟正解很像,但是把方格图分解成树形的时候出事了……
[Solution]
= 先看一个类似的题目
如果你觉得 “哪里类似了?”,请你再看一遍
给出一棵树,求树上所有简单路径的长度之和。
解法就是考虑每一条边的贡献,即有多少条路径会经过这条边。由于树上的每一条边都是割边,所以把这条边删去后原来的树会变成两个连通块,不难发现从某一个连通块的节点到另一个连通块的节点的路径一定会经过割边。所以乘法原理——该边的贡献就是两个连通块的大小之积。
统计所有边的贡献即可。
或者这样统计,记树上有 n 个节点,第 i 个节点的子树大小为 siz[i],那么答案就是
这样,上面这道题就解完了。
= 剖分成树(不是树链剖分)
我们考虑剖分两次,第一次横着,第二次竖着,煮个栗子:
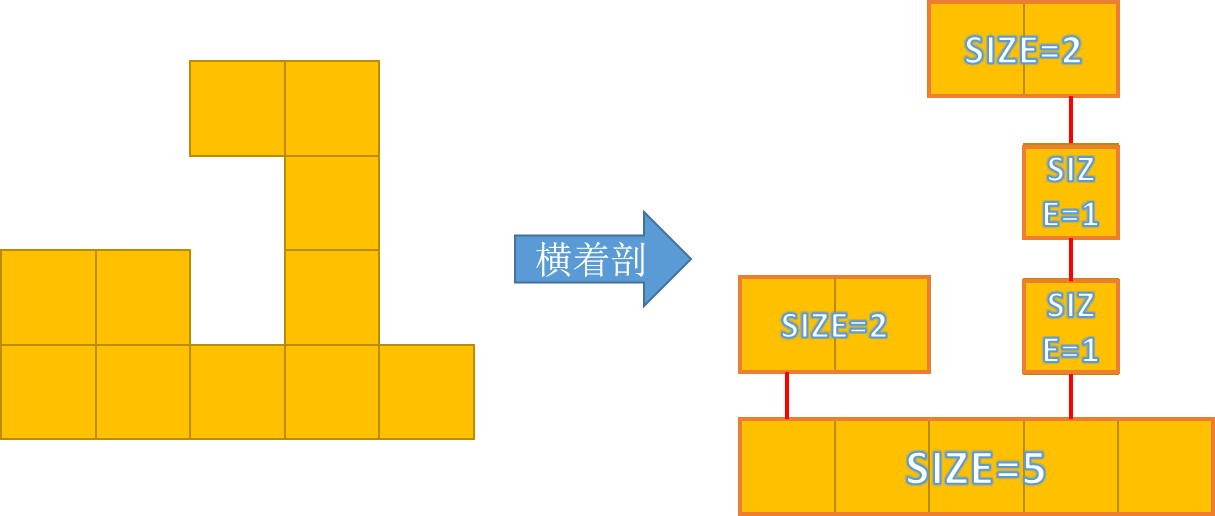
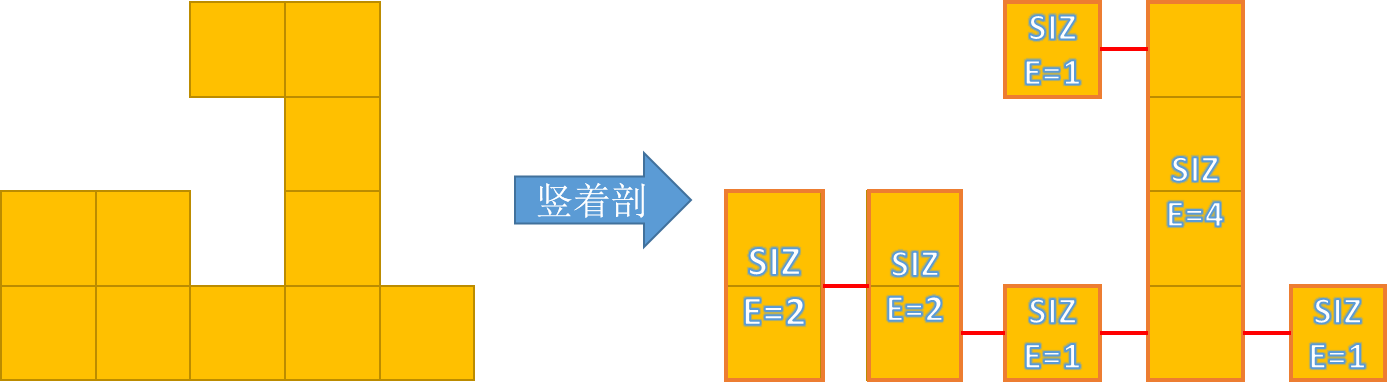
……其实我们就是求两棵树中红色边的贡献,只是说每个节点的大小不是 1,而是这个节点所代表的块中的方格的数量。
按照之前类似的问题的方法来求解即可。
剖分有一点麻烦,反正我是用的 map 和 set 来将原图划分的……
[Source]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
#include<set>
#include<map>
#include<cmath>
#include<queue>
#include<stack>
#include<vector>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const ll MOD=1e9;
const int N=1e5;
struct PAIR{
int x,y;
PAIR(){}
PAIR(int _x,int _y):x(_x),y(_y){}
}pos[N+3];
bool operator <(const PAIR cpr1,const PAIR cpr2){return cpr1.x==cpr2.x? cpr1.y<cpr2.y:cpr1.x<cpr2.x;}
bool cmpPAIRx(const PAIR cpr1,const PAIR cpr2){return cpr1.x==cpr2.x? cpr1.y<cpr2.y:cpr1.x<cpr2.x;}
bool cmpPAIRy(const PAIR cpr1,const PAIR cpr2){return cpr1.y==cpr2.y? cpr1.x<cpr2.x:cpr1.y<cpr2.y;}
int n,nump;
int sizp[N+3];
set<int> lnkp[N+3];
map<PAIR,int> extp;
ll ans;
void DFS(int u,int pre){
for(set<int>::iterator it=lnkp[u].begin();it!=lnkp[u].end();it++){
int v=*it;
if(v==pre) continue;
DFS(v,u);
sizp[u]+=sizp[v];
}
ans=(ans+1ll*sizp[u]*(n-sizp[u])%MOD)%MOD;
}
int main(){
freopen("city.in","r",stdin);
freopen("city.out","w",stdout);
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d%d",&pos[i].x,&pos[i].y);
extp.clear();
for(int i=1;i<=n;i++)
lnkp[i].clear(),
sizp[i]=0;
nump=0;
sort(pos+1,pos+1+n,cmpPAIRx);
for(int i=1;i<=n;i++){
if(!(pos[i].x==pos[i-1].x && pos[i].y==pos[i-1].y+1))
nump++;
sizp[nump]++;
extp[pos[i]]=nump;
PAIR lef=PAIR(pos[i].x-1,pos[i].y);
if(extp.count(lef))
lnkp[nump].insert(extp[lef]),
lnkp[extp[lef]].insert(nump);
}
DFS(1,0);
extp.clear();
for(int i=1;i<=n;i++)
lnkp[i].clear(),
sizp[i]=0;
nump=0;
sort(pos+1,pos+1+n,cmpPAIRy);
for(int i=1;i<=n;i++){
if(!(pos[i].y==pos[i-1].y && pos[i].x==pos[i-1].x+1))
nump++;
sizp[nump]++;
extp[pos[i]]=nump;
PAIR flr=PAIR(pos[i].x,pos[i].y-1);
if(extp.count(flr))
lnkp[nump].insert(extp[flr]),
lnkp[extp[flr]].insert(nump);
}
DFS(1,0);
printf("%lld\n",ans);
return 0;
}
|
The End
Thanks for reading!
Email: lucky_glass@foxmail.com ,欢迎提问!